Million Song Dataset Analysis
Team Members: Leonardo Tang, Sahir ShahryarIntroduction
We are going to analyze the Million Song Dataset (MSD) in order to see if trends in music can be predicted by using music metadata.
Supervised Learning: Hit Prediction
There has already been some research into using supervised learning techniques to classify songs’ emotion and artistic style [1, 2].
The MSD contains data about a song’s “hotness,” which is a measure of its short-term popularity at the time the song was added into the dataset [3, 4]. We would like to train a model that can predict, given every attribute except the hotness of a song, whether that song is a hit. In order to do this, we will deliberately exclude a random sampling of songs from the dataset, train the model on the remainder, and then test how accurately the model predicts the hotness of the excluded songs. If this approach shows promise, we will also build a model specifically using older songs and then test it on the newest songs in the MSD, to see if a model built with today’s hit music could hypothetically predict tomorrow’s. Hopefully, the model we build will help us predict which songs have that “hit” quality to them.
Unsupervised Learning: Genre Classification
The complementary datasets to MSD contain genre labels, user data, etc. We would like to train a model that can assign songs to a specific genre. To do so, we will employ k-means clustering, GMM, DBSCAN, and spectral clustering. K-means is fast, but doesn’t allow for anything other than spherical clusters, so we will also attempt DBSCAN and spectral clustering to account for differently shaped clusters in the feature space [5]. GMM provides a soft clustering approach that will help smooth out data points that mix genres. In the event where clustering doesn’t seem to align to genres, a more general interpretation of the clusters would be music recommendations from a holistic view, determined by all the features of the song rather than just genre. This model should hopefully return the genre of the song, and if not, the clusters in the model can be used for song recommendations.
Member Reponsibilities and Timeline
We were one of the groups formed at random. Unfortunately, one of the students in our group is auditing the course and another one will not be able to participate as they are taking a break for the fall semester. As such, we only have two active group members and have made a private post on Ed about our situation.
Assuming that our group issues are resolved, we will likely work on both the supervised and unsupervised aspects of our project side-by-side, so that any insights or discoveries we make while working with one technique can carry over to the other.
By the midterm report, we want to have trained the supervised model to identify hits, and we want to have tried at least k-means clustering and GMM in the unsupervised model.
References
[1] He, Hui, Jianming Jin, Yuhong Xiong, Bo Chen, Wu Sun, and Ling Zhao. Feature Mining for Music Emotion Classification via Supervised Learning from Lyrics. International Symposium on Intelligence Computation and Applications, 2008.
[2] Li, Tao, and Mitsunori Ohigara. Music artist style identification by semi-supervised learning from both lyrics and content. Proceedings of the 12th annual ACM international conference on Multimedia, October 2004.
[3] Million Song Dataset. An example track description.
[4] Lamere, Paul. Artist similarity, familiarity, and hotness. May 25, 2009.
[5] Dhillon, Guan, and Kulus. Kernel k-means, Spectral Clustering and Normalized Cuts.
[6] Jie and Han. A music recommendation algorithm based on clustering and latent factor model.
Midterm Progress Report
Cleaning, Feature Selection, and Initial Results
To get a quick start, we initially began working with a subset of the MSD which the authors of the project made available for direct download. The full dataset, which is roughly 280 GB in size, must be downloaded using an Amazon EC2 instance. This process has proven quite cumbersome, so for now, we have decided to use just the subset. For the final project, we will likely use about 10-15% of the full dataset, or about 100,000–150,000 songs.
Once we downloaded the subset, as well as the litany of software required to read it, we were able to convert the data into a CSV format and store it. This required making an initial decision about which features to include and which ones to ignore. For now, these are the features we chose to include:
- Song title and artist (for readability - not used in training)
- Hotness (this is the target result, or `y`
- Duration
- Key signature of the song
- Loudness
- Musical mode of the songs
- Tempo of the song
- Time Signature of the song
- Artist hotness (the "trendiness" of the artist when the song was added)
- Artist familiarity (the name recognition of the artist)
- Year the song was released (not currently used for training)
Some of the features we chose to discard for this portion of the project include the following
- Tags the artist received on musicbrainz.org (We're not sure how to use this information)
- ID of the song on playme.com (While it is numeric, it doesn't really describe any quality of the song itself)
- MD5 hash of the song's audio
- Confidence values for the key signature, musical mode, tempo, or time signature (not sure how to effectively adjust the model based on these features)
- Per-section and per-segment breakdown of pitch, timbre, and loudness (doing so adds hundreds of features to each song, the exact number of features would be different for each song, and it's nearly impossible to align those features in any meaningful way)
We were initally opposed to including artist hotness and familiarity, as these may nust be stand-ins for a song's popularity, but eventually decided to include them because the dataset was constructed with these features in mind, i.e. the artist features were included in the underlying model of a song's hotness, so choosing to exclude them would negatively impact our results. Ideally, if we were to ignore the artist features, we would need a corresponding dataset where the song hotness value was made independently of the artist name.
With these features, we ran the gen_msd_csv()
function in hitprediction.py,
which reads from the 10,000 sample files in the Million Song Database
subset and adds the selected features into a CSV file. This required
some cleaning of the data as well: many of the entries in the
dataset (roughly 4,500 out of the 10,000 in the subset) had no
hotness score at all, making them unusable for the classification
portion of our project. These songs, as well as a few stray songs
which had no scores for artist familiarity or hotness, were filtered out.
Logistic Regression
For logistic regression, the features that we chose were duration, key, loudness, mode, tempo, time signature, artist familiarity, and artist hotness. 80% of the songs were set aside as training data while the remaining 20% were used for testing purposes. For our labels, we based them on the song hotness column, splitting the songs into two categories, “hit” or “not hit” based on their song hotness values. Any song with a song hotness value above the sample mean was deemed a hit, while any song with a song hotness value below the sample mean was deemed not a hit.
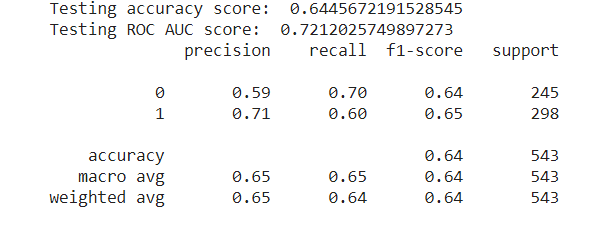
We ran a Logistic Regression model (courtesy of the sklearn library) with a maximum of 10,000 iterations until convergence. The accuracy score on the test data was around 64.46%, and the ROC-AUC (Area Under the Receiver Operating Characteristics) score was 72.12%. To be more specific, the classification report is as follows. For “not hit”, we achieved a precision score of 59% and a recall score of 70%, while for “hit”, we achieved a precision score of 71% and a recall score of 60%.
Naive Bayes
We also tried using naive Bayes to classify songs as either a hit or not a hit (using the same rule as for logistic regression). First, to reduce the number of features being used, we used k-best feature selection, with the scoring metric being an analysis of variance. (We also tried using χ^2, but this was not suitable as loudness values are stored in decibels (dB), which can be negative.) Using these features, we used sklearn’s GaussianNB class to test the model, with 80% of the data being used for training and 20% for testing. Before adding in the artist familiarity and hotness values to the dataset, using 4-best feature selection led to us using the key, mode, tempo, and time signature to predict whether or not a song was a hit with ~55.5% accuracy.
Once we added in artist hotness and familiarity, using 4-best feature selection led to us using the mode, tempo, artist’s hotness, and artist’s familiarity to predict whether or not a song was a hit with 72.45% accuracy. Tweaking the number of features selected does not substantially affect the accuracy of the model:
| k | feature added to the model | accuracy |
|---|---|---|
| 1 | artist hotness | 69.71% |
| 2 | artist familiarity | 72.72% |
| 3 | mode | 71.56% |
| 4 | tempo | 72.45% |
| 5 | time signature | 71.92% |
| 6 | key | 72.01% |
| 7 | loudness | 72.63% |
| 8 | duration | 72.80% |
(Note that since we are selecting the k best features at each stage, the “feature added” column in the table above is cumulative. So, for example, for k = 3, the model included artist hotness, artist familiarity, and mode.)
We can see that while naive Bayes technically does best when given all eight of these features, the difference is almost imperceptible when compared to naive Bayes based simply on artist hotness and artist familiarity.
Remainder of the Semester
Over the course of the rest of the semester, we will work to iterate on the hit prediction model and start working with the other features in the dataset in order to work on genre classification using the unsupervised learning algorithms.